 ➡️
➡️
I've been floating the idea of making an OpenGL backend for FSR 2 for a while now. However, only recently have I acquired the motivation to actually do it. I knew that writing a bespoke TAA(U) implementation, let alone a good one, was a task worthy of the gods, so I wanted to defer it to them. I also found some other OpenGL users who were willing to integrate FSR 2. At that point, I figured my time had come.
Boy, am I glad you asked! FSR 2, or FidelityFX Super Resolution 2, is a temporal upscaling (TAAU) algorithm developed by AMD. It is comparable to Nvidia's DLSS, except it is completely open-source and doesn't require vendor-specific GPU features (tensor cores) to run. Here is a cool presentation going over algorithmic details and optimizations in FSR 2.
In other words, FSR 2 has two main uses:
To understand how to create a new backend for FSR 2, we need to understand how it is structured.
FSR 2 has a modular design, allowing us to connect the frontend to any backend of our choice. This design makes it much easier to implement support for an API of our choosing (OpenGL in this instance), as we don't have to understand the intricacies of the FSR 2 algorithm.

Armed with this knowledge, let's jump into the source to see what we're up against!
The VK and DX folders, despite what I initially thought, did not contain the Vulkan and DX12 backends for FSR 2. These were the sample projects using Cauldron, which we aren't interested in.
Opening ffx-fsr2-api revealed what we were looking for.
The frontend can be found in ffx_fsr2.cpp, while the premade backends are located in dx12/ffx_fsr2_dx12.cpp and ffx_fsr2_vk.cpp.
So far so good! The shaders used by the backends can be found in shaders/, naturally.
An absolute chonker of a directory! One thing to note is that the shaders are quite modular as well- the FSR 2 passes are implemented in the non GLSL/HLSL-specific header files.
At this point, there are three main things to do:
GL_KHR_vulkan_glsl, adding a few incompatibilities).Since the shaders are the heart of the FSR 2 algorithm (and everything else is essentially support code), it makes sense to start here first. This will reveal the shading language requirements of FSR 2, which will determine whether this is possible or not.
Scrolling through the GLSL-specific shader sources, I found that the following extensions are used:
.glsl2. Creative, I know.
ffx_fsr2_callbacks_glsl.h contains all the resource declarations and definitions of accessor functions. This file contained most of the incompatibilities caused by GL_KHR_vulkan_glsl and GL_EXT_samplerless_texture_functions.
Despite samplers and textures being separate objects in OpenGL, GLSL (without GL_KHR_vulkan_glsl) annoyingly only supports combined texture-samplers. Porting separate samplers and textures in shaders is straightforward- just make a sampler2D for each combination thereof. I was initially afraid of a combinatorial explosion, but it turns out that only one sampler (linear, edge clamp) is actually used when calling the texture* functions. All other texture access came from texelFetch, which didn't care about the sampler (and is the rationale behind GL_EXT_samplerless_texture_functions). The other incompatibility from this extension was caused by the set = 1 layout qualifier on all resource declarations. Fortunately, the fix was as shrimple as deleting those.
GL_EXT_shader_image_load_formatted is a neat extension that I learned about while browsing the GLSL sources. This extension doesn't appear to be necessary (all non-writeonly images I saw had a format qualifier), but I kept it since it is supported by the major OpenGL vendors, and I wanted to change the shaders as little as possible.
GL_KHR_shader_subgroup_quad is a subset of the functionality exposed by GL_KHR_shader_subgroup, again a reasonably well-adopted extension.
I couldn't find a cross-platform OpenGL analogue of GL_EXT_shader_16bit_storage, but it didn't matter since the shaders compiled with or without the extension (and both NV and AMD drivers would ingest SPIR-V that contained the extension).
GL_EXT_shader_explicit_arithmetic_types is used to expose the faster FP16 types for certain passes. OpenGL drivers do not advertise support for this extension explicitly, but I found that, like the previous one, the drivers would happily ingest it anyways. If that wasn't the case, the important parts can be exposed by enabling GL_NV_gpu_shader5, GL_AMD_gpu_shader_half_float, and GL_AMD_gpu_shader_int16. I only didn't do that because glslang spat out some scary warning about GL_NV_gpu_shader5 not being recognized.
As you may already know, Vulkan essentially only accepts shader code in the form of SPIR-V. What this practically means is that you (literally you, the application programmer, whom I point my finger at) must invoke some third-party compiler at some point to transform GLSL (or HLSL, or any number of relatively esoteric shading languages) into SPIR-V. FSR 2 compiles shaders with a tool called "FidelityFX_SC.exe". The tool is used to invoke dxc, fxc, or glslang (depending on the source language), and uses special syntax to automatically generate shader permutations. It also generates C++ headers containing reflected resource bindings, the shader binary, and the permutation flags to make it easy to consume in the application.
OpenGL, on the other hand, consumes shaders as raw-ass GLSL. This would clearly be a major blocker as I'd have to rewrite the shader tool (whose source is unavailable) to make it output text (and no, the -E flag to output preprocessed text did not work). Too bad OpenGL doesn't support SPIR-V. Well... unless?
Thankfully, OpenGL supports SPIR-V, so we can use the existing infrastructure with relatively little intervention. We simply replace the shader compiler flag --target-env vulkan1.1 with --target-env opengl --target-env spirv1.3 to target OpenGL and use GL_KHR_shader_subgroup.
I know, it's 2023 and it has been a while since you got to see a pretty picture. Savor this respite from the madness.

A backend for FSR 2 consists of two major components:
Overall, this process wasn't terribly interesting. I started by copying the Vulkan backend's interface to OpenGL (some of the comments may even be the same if you're viewing this early enough). Then, I copied the bulk of the Vulkan backend and removed the Vulkan headers, revealing the work that I had to do.

Some highlights include:
Performance was something that I hoped would "just work" for both vendors (since the shaders were practically the same). Unfortunately, in the case of Nvidia, I ran into an issue.
FSR 2 ran about 3x slower than expected on my RTX 3070 due to high VRAM throughput in the depth clip pass and reproject & accumulate pass. These are the third and fifth passes as denoted by the blue markers in the "Draw/Dispatch Start" row.
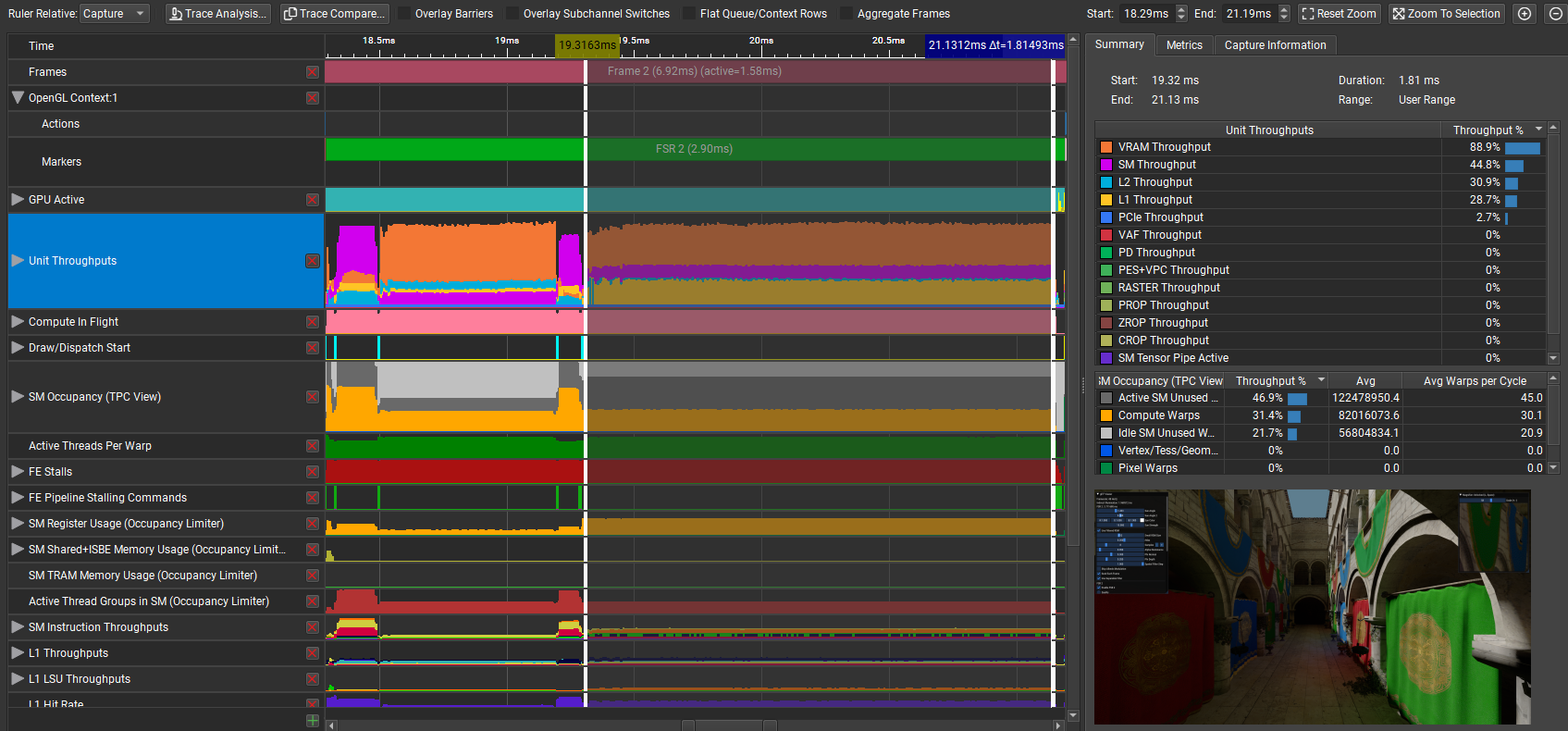
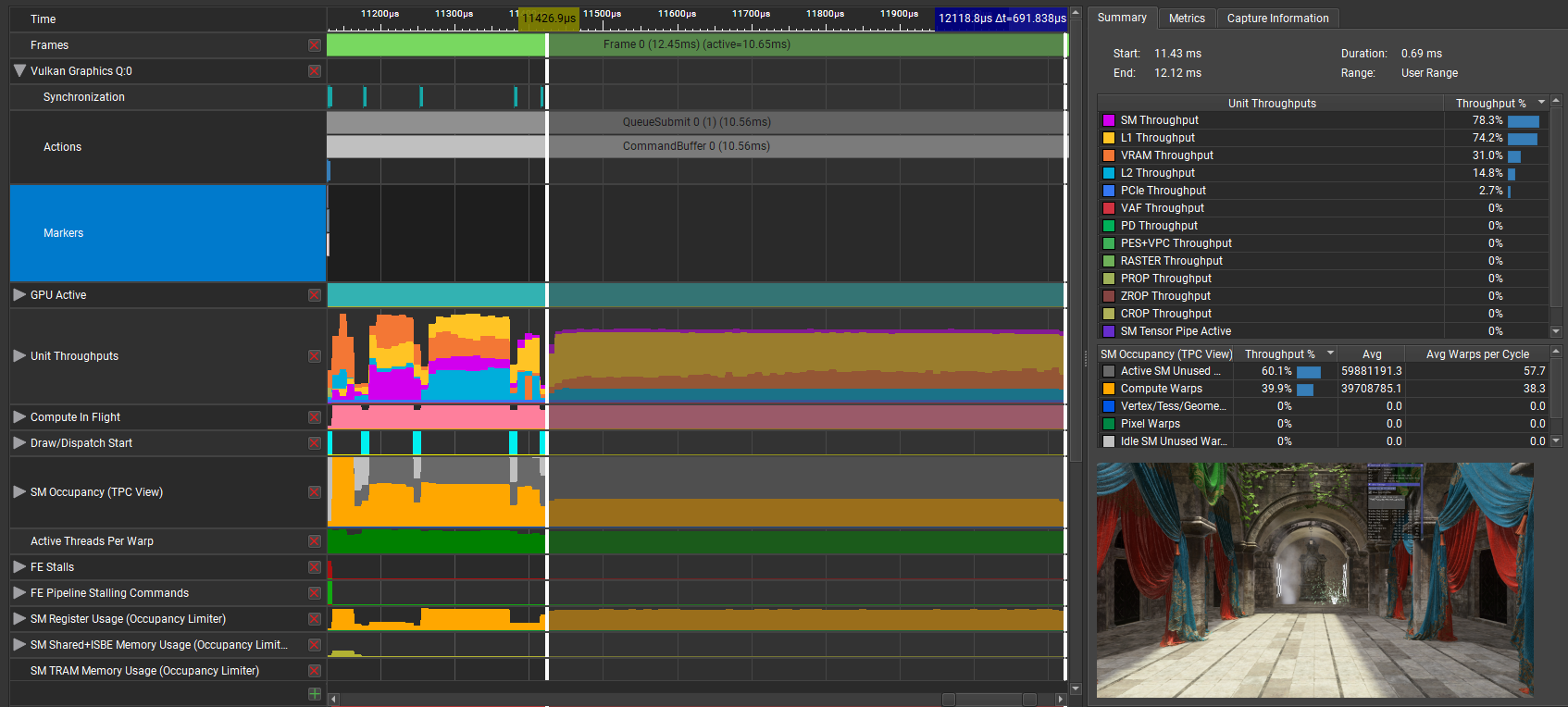
Compare this graph with that of the Vulkan backend running under Cauldron (the framework used to test FSR 2). Note that VRAM throughput is much lower, while other (faster) units have much higher throughput.
The only hint I have that points to the cause is this code found in the Vulkan backend:
// Workaround: Disable FP16 path for the accumulate pass on NVIDIA due to reduced occupancy and high VRAM throughput.
if (physicalDeviceProperties.vendorID == 0x10DE)
supportedFP16 = false;In conclusion, I do not know what is causing the performance to vary drastically between backends. My best guess is that the shader compiler uses different heuristics based on the API, leading to different code generation.
On AMD, however, performance was exactly as expected on my RX 6800. No further investigation was required there.
The most cursed issue I ran into was a difference in how images units were represented in OpenGL and Vulkan. The Vulkan spec says this:
maxPerStageDescriptorStorageImages is the maximum number of storage images that can be accessible to a single shader stage in a pipeline layout.
The OpenGL spec says this:
Image units are numbered beginning at zero, and there is an implementation-dependent number of available image units (the value of MAX_IMAGE_UNITS).
Hopefully you can see the potential issue. Nvidia GPUs today support only 8 image units in OpenGL, which means the largest binding index we can use is 7. However, the Vulkan FSR 2 backend uses larger indices, since the limit there is only how many storage images can be bound.
The first solution I tried was using bindless textures and setting them with glUniform1i. I did not get far, as simply adding #extension GL_ARB_bindless_texture : require caused the shaders to not compile in glslang. I later found GitHub issues implying that the extension was supported, so I must have been using an old version of the compiler. However, I already moved on at this point.

The next idea I had was to use reflection data from the shader tool (FidelityFX_SC.exe) and set image bindings starting from zero at runtime. Essentially, something like this:
int currBinding = 0;
for (binding : imagesToBind) {
auto loc = glGetUniformLocation(program, binding.name);
glProgramUniform1i(program, loc, currBinding);
glBindImageTexture(currBinding, binding.image, ...);
currBinding++;
}
This worked! ...Until I ran the code on an RDNA 2 system, where the glProgramUniform1i calls inexplicably did nothing. After a long investigation, I discovered that mutating image bindings of SPIR-V shaders is not well-defined by the specs (both SPIR-V and OpenGL 4.6), which means it is perfectly understandable that an implementation or RenderDoc would not support this.

In my weakened state, I remembered that I still had a trick up my sleeve: --auto-map-bindings. This glslang option will make it automatically set resource bindings starting from zero, making it a seemingly perfect fit for this case.
Unfortunately, glslang exhibits finnicky behavior with this flag, as I found it difficult to control which resources got the smaller binding indices. This meant that images could still be assigned large binding indices, even if they were declared before the other resources (I couldn't reproduce this in a simple test shader though). In hindsight, this strategy would have worked if I assigned explicit high indices to the samplers and uniform buffers, but I didn't think of it at the time.

After facing three crushing defeats, I was desperate to find something that worked without requiring a huge refactoring of the shader-related code. In the command line options for glslang, an angel called to me:
--shift-image-binding [stage] num base binding number for images (uav)
--shift-sampler-binding [stage] num base binding number for samplers
--shift-UBO-binding [stage] num base binding number for UBOsI (ab)used my newfound powers to create this monstrosity:
set(FFX_SC_GL_BASE_ARGS
-compiler=glslang -e main --target-env opengl --target-env spirv1.3 --amb --stb comp 8 --ssb comp 8 --sib comp 0 --suavb comp 0 -Os -S comp -DFFX_GLSL=1)In short, several options are to ensure that images get priority on bindings 0-7, while other resource bindings start at 8. This is ultimately the solution that was used to solve this binding problem.
TODO: insert hilarious meme hereOf course, if OpenGL was a sane API, I wouldn't have had to deal with this mess. I'm just happy that it worked without requiring massive changes to FSR 2.
FSR 2 can work with various view-space depth configurations. It does so by generating constants that can be used to convert NDC-space depth to view-space. This is used in the depth clip pass. Here is the shader, for the curious.
As you probably suspect by now, the issue here is OpenGL's unhinged [-1, 1] device depth range not matching Vulkan's (and every other API's) device depth range of [0, 1]. This leads to the constants FSR 2 generates to give subtly wrong results. I didn't fully understand the derivation of the constants from the [0, 1] NDC projection matrix, so I did not derive my own constants to make the conversion correct for most OpenGL apps. However, note the following:
glClipControl, which allows the user to select the [0, 1] device depth range, bypassing this issue entirelyIntegrating FSR 2 is surprisingly straightforward. The basic engine requirements are as follows:
To test my port, I used a relatively basic glTF viewer sample originally developed as a sample for my OpenGL wrapper. Here are some pics to wrap things up.


Once again, big thanks to the peeps on the Graphics Programming Discord for their support, LVSTRI for inspiring me to finally start this project, and BoyBaykiller for creating C# bindings for this fork. And of course, big thanks to AMD (#notsponsored) and the team who worked on providing this wonderful open-source library.